
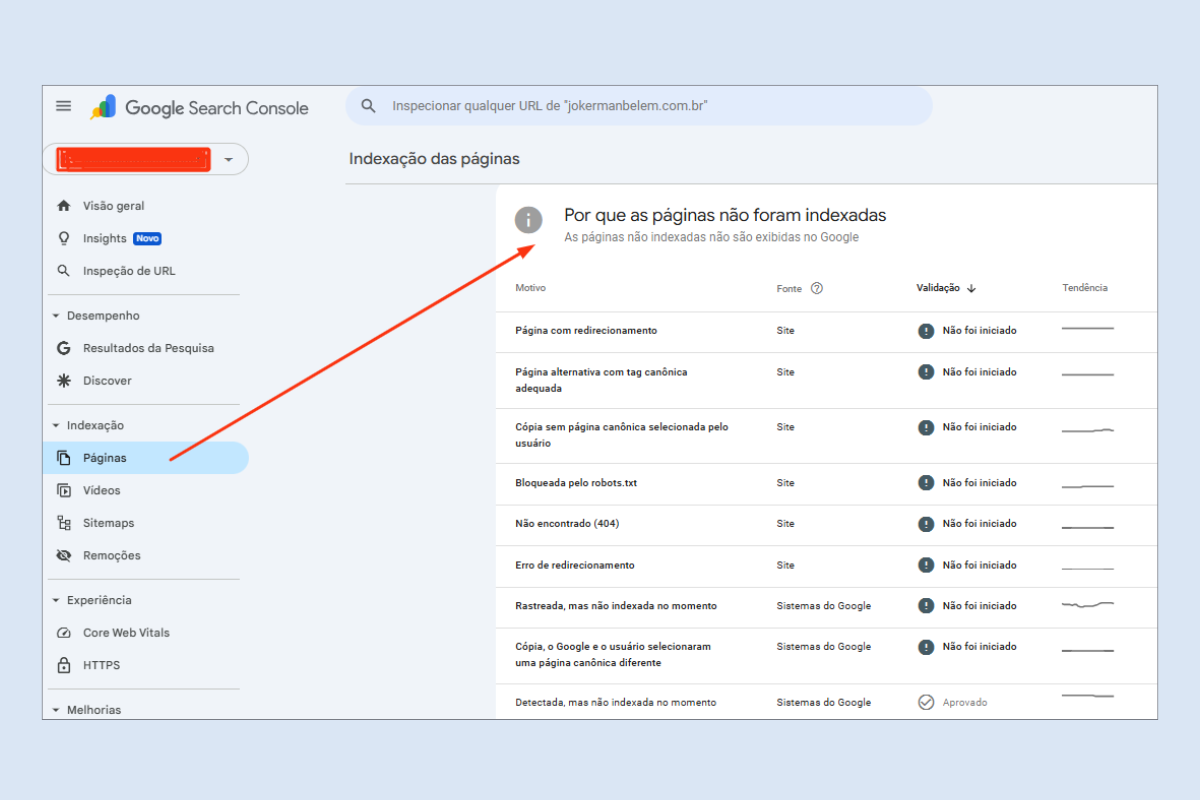
Encontrar o status “páginas não indexadas” no Google Search Console (GSC) costuma assustar. Afinal, se o Google não indexa, o conteúdo não aparece nas buscas e… isso significa tráfego perdido.
Mas a boa notícia é que esse relatório não é um castigo, mas um mapa de oportunidades. Ele mostra o que precisa ser otimizado para que seu site ganhe mais visibilidade.
Vamos explorar os principais status de exclusão, com foco especial em “Detectada, mas não indexada no momento” e “Rastreada, mas não indexada no momento”, que são os mais comuns (e confusos).
Antes de tudo: como funciona o processo de indexação
Antes de falar dos erros, vamos recordar as etapas que levam uma página até o índice do Google:
- Descoberta: o Google identifica que a URL existe (por links, sitemaps ou menções);
- Rastreamento: o Googlebot acessa a página e lê seu conteúdo;
- Indexação: o conteúdo lido é processado e armazenado no banco de dados do Google;
- Exibição: quando alguém pesquisa, o Google consulta o índice e mostra as páginas mais relevantes.
Se a página está “detectada, mas não indexada”, significa que o processo parou no passo 1.Se está em “rastreada, mas não indexada”, parou no passo 2.
Dito isto, vamos aos motivos das páginas não indexadas e como resolvê-los:
1. Detectada, mas não indexada no momento

O que significa: o Google sabe que a URL existe, mas ainda não tentou rastreá-la. Muitas vezes, isso ocorre porque o Google não quer sobrecarregar o servidor, então o rastreamento é adiado.
Causas mais comuns:
- Sobrecarga do servidor;
- Muitos conteúdos para rastrear ao mesmo tempo;
- Baixa qualidade percebida no domínio como um todo (este é um ponto de atenção!).
Como resolver:
- Solicite a indexação manual: se forem apenas algumas páginas, vá até o relatório de indexação no GSC, insira a URL e clique em “Solicitar indexação”. Essa ação força o Google a priorizar a página;
- Otimize o crawl budget: se o problema for grande, você precisa garantir que o Google gaste seu “orçamento de rastreamento” nas páginas mais importantes. Isso pode incluir bloquear URLs inúteis no arquivo Robots.TXT, usar canonicals corretamente e eliminar duplicidades;
- Melhore a linkagem interna: uma página que está a muitos cliques de distância da home ou não recebe links de outras se torna praticamente invisível. Trabalhe em menus, categorias e links contextuais para reforçar sua relevância;
- Eleve a qualidade do conteúdo: se o Google identifica padrões de baixa qualidade no site, ele tende a não investir esforço em rastrear novas páginas. Reescreva, atualize ou elimine conteúdos superficiais;
- Otimize o servidor: servidores lentos ou instáveis são um freio para o rastreamento. Use cache, CDN e monitore o tempo de resposta. O ideal é que esteja sempre abaixo de 500ms.
2. Rastreada, mas não indexada no momento
 O que significa: O Google acessou a página, leu o conteúdo, mas decidiu não adicioná-la ao índice.
O que significa: O Google acessou a página, leu o conteúdo, mas decidiu não adicioná-la ao índice.
Causas mais comuns:
- Conteúdo duplicado ou pouco original;
- Texto superficial (thin content);
- URLs redundantes ou geradas automaticamente;
- Pouca relevância (páginas órfãs, sem links internos).
Como resolver:
- Fortaleça os links internos: páginas sem conexões internas são vistas como irrelevantes. Crie links contextuais a partir de conteúdos mais fortes. Veja aqui como criar topic clusters;
- Revise a qualidade do conteúdo: se a página não agrega nada de novo, dificilmente será indexada. Acrescente dados, exemplos, imagens, comparações e informações originais;
- Use canonicals: se você tem variações muito semelhantes (ex.: versões com parâmetros), indique ao Google qual deve ser considerada a principal;
- Elimine redundâncias: quanto mais páginas similares, mais difícil fica para o Google entender qual merece destaque. Prefira consolidar em um único conteúdo completo.
3. Cópia sem página canônica selecionada pelo usuário

O que significa: o Google encontrou versões muito parecidas de uma mesma página, mas você não informou qual é a principal delas.
Como resolver:
- Defina páginas canônicas: adicione a tag rel=”canonical”apontando para a versão preferida;
- Consolide páginas duplicadas: em vez de ter várias páginas fracas, crie uma só mais completa;
- Controle parâmetros e versões: garanta que não existam múltiplas combinações de URL (como HTTP e HTTPS, ou com e sem www).
4. Não encontrado (404)
")
O que significa: o Google encontrou links para páginas que não existem mais. Por isso, sempre que há páginas não indexadas aqui, significa que alguém se perdeu no caminho.
Como resolver:
- Corrija links internos quebrados: revise menus, páginas, artigos antigos e rodapés para eliminar referências erradas;
- Redirecione URLs relevantes: se a página já recebeu links externos ou tinha tráfego, crie um redirecionamento 301 para outra página equivalente;
- Ignore URLs sem valor: se não existir link interno nem backlinks, deixar como 404 não prejudica o site.
5. Página com redirecionamento

O que significa: o Google encontrou a URL, mas ela leva diretamente para outra página por meio de um redirecionamento (geralmente 301 ou 302).
Como resolver:
-
- Se o redirecionamento for intencional (ex.: versão antiga de artigo redirecionando para a nova), não há problema;
- Se for acidental, revise regras de redirecionamento no servidor, .htaccess ou CMS para garantir que não existam loops ou caminhos desnecessários;
- Evite cadeias longas de redirecionamentos: idealmente, deve ser apenas 1 salto entre a URL antiga e a nova.
6. Página alternativa com tag canônica adequada

O que significa: o Google detectou que essa página é uma versão duplicada de outra e respeitou a indicação de canônica. Isso é positivo: quer dizer que o buscador entendeu qual URL você considera principal.
Como resolver:
- Se a configuração for proposital, não é preciso mudar nada;
- Se houver engano, revise se a tag rel=”canonical” aponta para a URL correta;
- Evite excesso de duplicação: quanto mais variações inúteis, mais difícil fica manter a consistência.
7. Bloqueada pelo Robots.TXT

O que significa: a URL foi descoberta, mas não pôde ser rastreada porque você (ou seu desenvolvedor) a bloqueou no arquivo Robots.TXT.
Como resolver:
- Se a página não deve ser indexada, está tudo certo. Ex.: áreas de teste, carrinho de compras, páginas de filtro ou duplicadas;
- Se deveria ser indexada, edite o arquivo robots.txt e remova a regra que impede o rastreamento;
- Lembre-se: bloquear via robots.txt não remove páginas do índice. Se a página já estava indexada antes, use a meta tag noindex no HTML.
8. Erro de redirecionamento

O que significa: o Google tentou seguir a URL, mas encontrou um problema no redirecionamento. Assim, a quantidade de páginas não indexadas aqui, pode estar acontecendo por:
- Loops infinitos (URL A → URL B → URL A);
- Cadeias muito longas (A → B → C → D…);
- Redirecionamentos mal configurados (302 usado quando deveria ser 301, por exemplo).
Como resolver:
- Teste a URL em ferramentas como o Redirect Checker para identificar a sequência;
- Conserte loops ou cadeias: idealmente, a URL original deve levar direto para o destino final em um único redirecionamento;
- Padronize os códigos: use 301 para redirecionamentos permanentes e 302 apenas quando for temporário.
Você pode gostar destes conteúdos também:
O relatório de páginas não indexadas é um instrumento estratégico
Ele mostra exatamente onde você está perdendo eficiência no SEO e onde pode melhorar. Então, resumindo, o que você pode fazer:
- Poucas páginas afetadas → solicite indexação manual e monitore;
- Muitas páginas ou recorrência → investigue orçamento de rastreamento (crawl budget), qualidade de conteúdo, linkagem interna e servidor.
“SEO é como jardinagem: é preciso podar o que não serve, nutrir o que é forte e garantir que cada parte do site contribua para um ecossistema saudável.“
Perguntas frequentes (FAQs) sobre páginas não indexadas
Acima, você viu os motivos que fazem com que as páginas de um site não sejam indexadas. Agora, vamos a uma lista de dúvidas comuns sobre o assunto? Aqui está:
1. O que significa “páginas não indexadas” no Google Search Console?
Páginas não indexadas são URLs que o Googlebot (o robô de rastreamento do Google) descobriu que existem, mas que não foram adicionadas ao índice (o banco de dados) do Google.
O índice é onde o Google armazena todas as páginas que ele considera relevantes e de qualidade. Se uma página não está no índice, ela não pode ser exibida nos resultados de pesquisa (SERP), resultando em perda de tráfego.
Os motivos podem ser técnicos (como o bloqueio pelo Robots.TXT) ou de qualidade (como a detecção de conteúdo duplicado ou superficial), conforme detalhamos neste artigo.
2. Como faço para indexar meu site no Google Search Console?
O processo de indexação é feito pelo Google automaticamente, mas você pode acelerá-lo e gerenciá-lo com o Google Search Console. Aqui está o que você pode fazer:
- Solicitação Manual (para URLs específicas): Use a ferramenta Inspeção de URL no topo do GSC. Insira a URL que você quer indexar e clique em “Solicitar Indexação”. Isso faz com que o Google priorize o rastreamento daquela página;
- Envio do Sitemap (para o site inteiro): Garanta que seu sitemap (o mapa de URLs do seu site) esteja submetido e atualizado na seção Sitemaps do GSC. Isso ajuda o Google a descobrir todas as suas páginas importantes;
- Correção dos Erros: A principal ação é corrigir os problemas de rastreamento e qualidade (como “Detectada, mas não indexada” ou “Erro de redirecionamento”) listados no seu relatório de Cobertura. O Google só indexa o que ele consegue rastrear e o que ele considera valioso.
3. O que é o “Orçamento de Rastreamento” (Crawl Budget) e como ele afeta a indexação?
O Orçamento de Rastreamento (Crawl Budget) é o limite de páginas que o Googlebot (robô de rastreamento do Google) está disposto a rastrear no seu site em um determinado período.
Se seu site tem muitas páginas de baixa qualidade, duplicadas ou bloqueadas de forma inadequada, o Google pode “gastar” seu orçamento em URLs inúteis, deixando as páginas importantes para trás. Isso resulta em status como “Detectada, mas não indexada no momento”.
Para otimizar o crawl budget, você pode fazer o seguinte:
- Bloquear URLs sem valor via Robots.TXT;
- Eliminar thin content ou páginas duplicadas.
- Garantir que o servidor tenha um tempo de resposta rápido (idealmente abaixo de 500ms).
4. Por que minha página aparece como “Rastreada, mas não indexada” mesmo tendo um conteúdo completo?
Este status indica que o Googlebot leu a página, mas decidiu que ela não merecia entrar no índice. Isso não por um erro técnico, mas por uma avaliação de qualidade ou relevância. As causas mais comuns, mesmo em conteúdos longos, são:
- Conteúdo superficial ou duplicado: o tema já está exaustivamente coberto em outros lugares do seu próprio site (redundância) ou na web, e o seu artigo não oferece uma perspectiva, dado ou valor original;
- Falta de relevância estrutural: a página está muito longe da home ou de outras páginas fortes (ou seja, é uma página órfã), não recebendo links internos para reforçar sua importância.
Solução: Reforce a linkagem interna para a página e adicione mais dados originais, estudos de caso ou exemplos que tornem seu conteúdo verdadeiramente único e mais forte.
5. Devo remover páginas com o status “Não encontrado (404)” do Google Search Console?
Não necessariamente. O status 404 significa que o Google tentou acessar uma página que não existe mais. Isso pode ser natural com o tempo. Então, você só precisa intervir se a URL 404 atender a um desses critérios:
- Possui links internos quebrados no seu próprio site. Nesse caso, você deve corrigir os links;
- Possui links externos (backlinks) valiosos ou gerava tráfego no passado. Nesse caso, você deve implementar um Redirecionamento 301 para uma página similar e relevante.
Se a página não tinha valor nem links internos, você pode deixá-la como 404. Com o tempo, o Google deixará de rastreá-la e o status será removido do relatório.
6. Na prática, qual é a diferença entre o bloqueio por Robots.TXT ou pela tag NoIndex?
Eis que temos duas opções de bloqueio que sempre geram dúvidas. Então vamos lá:
Como funciona o bloqueio pelo Robots.TXT:
AÇÃO |
USO IDEAL |
RISCOS |
Impede o rastreamento do conteúdo |
Páginas que não precisam ser lidas pelo Google, como arquivos de mídia ou URLs de filtro/parâmetros (para otimizar o crawl budget) |
Se uma página for bloqueada e também tiver links externos fortes, ela pode ser indexada mesmo assim (sem título ou descrição), pois o Google não conseguiu ler o comando “noindex” |
Como funciona o bloqueio pela tag NoIndex:
AÇÃO |
USO IDEAL |
RISCOS |
Permite o rastreamento, mas impede a indexação |
Páginas que o Google pode rastrear para ver links internos, mas que você não quer que apareçam nas buscas (ex.: página de agradecimento após uma compra) |
Não há risco de indexação indesejada, pois o Google lê a tag antes de decidir indexar. |
Conseguimos te ajudar com este conteúdo? Deixe um comentário!




